Datatype: SQL DB#
In this example, we are using the gcbm_output.db file.
In order to open a SQL file in a jupyter notebook, you need to import the sqlite3, pandas and sqlalchemy libraries.
Follow the given steps to open a SQL file:
Import sqlite3, pandas and sqlalchemy modules
import sqlite3
import pandas as pd
import sqlalchemy
Create a read-write connection
conn = sqlite3.connect("gcbm_output.db")
Create a cursor object
curs = conn.cursor()
To list all the tables in the database, use the cursor’s fetchall() method to get the tables listed in sqlite_master
curs.execute("SELECT name FROM sqlite_master WHERE type = 'table'").fetchall()
[('ClassifierSetDimension',),
('DateDimension',),
('PoolDimension',),
('LandClassDimension',),
('ModuleInfoDimension',),
('AgeClassDimension',),
('LocationDimension',),
('DisturbanceTypeDimension',),
('DisturbanceDimension',),
('Pools',),
('Fluxes',),
('ErrorDimension',),
('LocationErrorDimension',),
('AgeArea',),
('sqlite_stat1',),
('r_change_type_categories',),
('sqlite_sequence',),
('r_pool_collections',),
('r_pool_collection_pools',),
('r_flux_indicators',),
('r_flux_indicator_collections',),
('r_flux_indicator_collection_flux_indicators',),
('r_stock_changes',),
('r_pool_indicators',),
('r_location',),
('r_stand_area',),
('v_flux_indicators',),
('v_flux_indicator_aggregates',),
('v_stock_change_indicators',),
('v_pool_indicators',),
('v_disturbance_indicators',),
('v_age_indicators',),
('v_error_indicators',),
('v_total_disturbed_areas',),
('v_disturbance_fluxes',),
('v_flux_indicators_density',),
('v_flux_indicator_aggregates_density',),
('v_stock_change_indicators_density',)]
fetchall() returns a list of tuples, and in this case each tuple has a single element, which is why they each have a trailing comma.
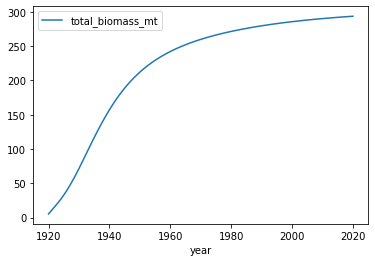
Here is an example of a map that gives out the total biomass from the year 1920 to 2020
query = f"""
SELECT years.year, COALESCE(SUM(i.pool_tc), 0) / 1e6 AS total_biomass_mt
FROM (SELECT DISTINCT year FROM v_age_indicators ORDER BY year) AS years
LEFT JOIN v_pool_indicators i
ON years.year = i.year
WHERE i.indicator = 'Total Biomass'
AND (years.year BETWEEN 1920 AND 2020)
GROUP BY years.year
ORDER BY years.year
"""
df = pd.read_sql_query(query, conn)
ax = df.plot.line("year")